|
This week was very productive. I spent hours researching why my Redfin scraper appeared to be skipping statements causing it to crash. I finally learned that the reason this was happening was because when a selenium web driver interacts with a webpage is such a way that causes the page to load/reload, we have to also write a script that will stop the script from executing the next statement until the page has completed loading; Selenium does not know to wait for a page to load, so if the page does not load quick enough, the next statement will be executed to soon, and this is exactly what was happening to me. Thanks to Harry J.W. Percival, the author of Test-Driven Development with Python, he covers how to resolve this issue on his blog. I then took what I needed from that post and incorporated it into my script. To test the new wait method, I added a condition to only scrape Arizona properties. After a few hours, the script completed without any errors. I then felt confident enough to allow the script to scrape the remaining states. This process took 5 days to complete (slowness is the downside of using Selenium, because it requires an actual browser to make the calls).
Because the script goes to every city and downloads a unique csv file to a designated folder, I ended up with a folder with almost 9,000 csv files. The next step is to convert all of the data to JSON format, so I needed a way to combine all of the files into one. I did not want to do this manually, so I look into way to automate this process. After researching Pythons libraries and found a way to search for all csv files in a given directory and write each file into a new one. This worked out pretty well and I now have all of the property data I scraped from every state in one file. I have yet to convert the data to JSON. While the script was running, I took the time to organize all of my scrapers and data, then push them to our Github repository for this project.
2 Comments
My Goals for this week was to get my Redfin scraper to work. I was finally able to find a way to automate the download with Selenium. I found that the reason I was unable to download was due to the additional prompt browsers display that give the option to either save, or open the file. Selenium has a method that allows you to set the webdriver to ignore the prompt and download in a given location. Once I applied the changes, I tested it by loading a site that had the download link: https://www.redfin.com/city/18607/AZ/Tempe. I then used selenium to search for and click the download link, and it worked. My next step was to make it automate the download for every city in the US. The reason I had to search by city was due to the input validation done on Redfin's website. The search box will not function unless provided an accepted format - City, State being the largest area that can be searched. Search by only It was actually quite difficult to get a list of every city in the US that was free. Zip codes are accepted, but there are a lot more zip codes then there are cities; therefore, the time it would take to complete the script would increase. When I did find a free resource, they were generally incomplete, or organized in a non-intuitive way. I eventually found what I needed, and was able to reformat it to be used as input for my script. I thought I had it figured out, but then I ran into a lot of issues when trying to automate the download for every city. First, there were a few checks I needed to include in the script to handle the faults on Redfin's site. One fault that would occur is when a city and state is provided that is not recognized by Redfin, it would display a pop-up window with suggestions for other cities. To handle this, I had to add a check to verify the current url did not change; if the url did not change, then I know the fault had occurred. If the fault occurred, I would reload the site, then search the next city. Another fault that I noticed was that it would sometimes load the page for a given city, but the city would not have any listings nor download link. To handle this fault, I included a try catch block to catch the NoSuchElementException that is thrown when the download link is not present. 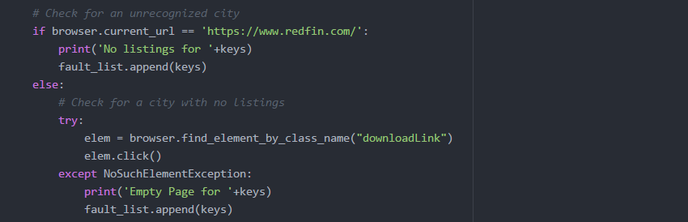 Once I handled the possible faults, I thought I was finished, but then I ran into other issues. The script would run fine for a few cities, then it would get buggy. There seemed to be random issues with Selenium loading a site, download the csv file, and finding elements. I monitored the script as it would run, then I would see it load a site for a city, download the csv file, then instead of following the script by going back to the main webpage redfin.com, it would instead skip to searching for the next city on the listings page. Below is a screenshot of an example:  As you can see, the site loaded for Tempe (see url), but after the download it did not go back to the main redfin.com, instead it searched Tolleson in the search box above. This would not be an issue if the site was able to recognize every city, but due to the fault explained earlier, if Tolleson was not in their list of valid cities, it would crash my script. I could not figure out why this would occur. My assumption would be that it was due to the inconsistent loading times, so I began researching the different wait methods. I first decided to bring in Python's time library to use the sleep function. This will force my script to stop for a given amount of time, then continue. It did seem to improve the script by completing a few more cities before crashing, but it would eventually crash. I knew that approach was risky, because the time for a page to load is inconsistent. I then found Selenium's explicit wait method that waits for a certain condition to occur before proceeding further in the code.
This weeks goal was to obtain real estate data. I began by researching the most common and well known real estate websites: Zillow, Trulia, and realtor.com. I was hoping one of these sites will have API's that are not too restricted. Zillow's API only allows you to obtain property data for a specified address, so we will not be able to obtain all of the properties that are on the market. Afterwards, I looked into Trulia's API and they only allowed you to review general data regarding cities and states, which will also not help us locating properties that are for sale. I then began looking into realtor.com, but I was not able to locate an API on their website. I learned that getting this data would not be simple, because of the importance these leads have in the world of real estate. I found blog posts on sites like Quora where other people were looking to obtain the same data, and I learned that MLS data is usually only provided to realtors and brokerages that are members of a specific MLS. After learning this, I had to resort to web scraping.
My next goal was to try to find a website with a friendly web-scraper format. Many of the sites only listed a few properties and were paginated, so writing a script for that may be complicated. Also, many of the sites were JavaScript rendered pages, which we are not able to scrape using the beautiful soup and standard Python libraries. I did find one website that provided a unique feature that I was not able to find on any other real estate website. redfin.com allows you to search for by city and returns a list of all properties for sale in the city. Not only does it provide a list, it provides a link to download the entire list in csv format! I was really excited to find this, because I thought it will make writing a scraper much simpler. After studying the sites url structure to see how I would go about getting every city's list, I found that a unique ID was given for each state, which will made writing the scraper a bit more complicated. Since the unique id was being used on the site, I will need to write a script to automate entries on their main search function. I need to pass every city in the US into the search field and then locate the download link on each site. This of course will require me to read JavaScript rendered pages. Since redfin.com contained JavaScript rendered pages, I knew that I would need to research methods that will allow me to scrape it. Saul also ran into this issue with the data he was gathering and was able to locate some tools that are said to scrape JavaScript rendered data. The two he introduced me to was Ghost.py and PhantomJS. After learning about the two, Ghost.py seemed familiar to Selenium, which was a tool I used when I was trying to use a JavaScript tool that provided the latitude and longitude for a given address. I was able to get that to work, but the performance was not good, because it actually opened a automated the steps provided in the script. The tool was mainly used for acceptance testing. What made Ghost.py different was that it performed the same tasks, but with a headless browser which improves performance. So I went through the installation process by installed Ghost.py, then I learned it required and additional library; I can either install pyside, or pyQT. The issue I had was since I was running Python 3.5, neither of those libraries was supported. I did not was to downgrade, because many of my other scripts relied on the 3.5 version. I then tried PhantomJS. PhantomJS is a standalone headless browser, so I can use selenium like I did before, but instead of calling a normal browser like Firefox to test the script, I will be able to use the PhantomJS headless browser. I wrote a quick script to run against the redfin site that will open the site, enter "Tempe, AZ" in the search box, then click on the download link. The script failed when it go to locating the search box by it's class name. I could not find a mistake in the code I wrote, so I tested it using Firefox instead of PhanomJS. Using Firefox it was able to find the search box, enter Tempe, and load the Tempe site with the list and download link, but failed when trying to locate the download link. After researching why PhantomJS would not work, a lot of people that had similar issues found that there was a bug and a way to get around it was by applying a window size to the PhantomJS browser. I tried this, but continued to have the same issue. I was not able to find a solution to the PhantomJS issue, so I decided to stick to selenium and Firefox, but I still needed to figure out the issue not being able to click the download link. After spending some time researching and testing, I found that I made a mistake writing the click statement, so I made the adjustment and confirmed that my code is in fact locating the download link. The issue I had next was getting the click method to actually download the file. I read online that I could try adjusting my browser's download setting to not prompt and automatically store downloads in a specific folder. After trying, it still did not download. I will need to continue to research this issue. Once I am able to get the download link to work, I will be able to gather all properties for sale in the US along with the following data: SALE TYPE, HOME TYPE, ADDRESS, CITY, STATE, ZIP, LIST PRICE, BEDS, BATHS, LOCATION, SQFT, LOT SIZE, YEAR BUILT, PARKING SPOTS, PARKING TYPE, DAYS ON MARKET, STATUS, NEXT OPEN HOUSE DATE, NEXT OPEN HOUSE START TIME, NEXT OPEN HOUSE END TIME, RECENT REDUCTION DATE, ORIGINAL LIST PRICE, LAST SALE DATE, LAST SALE PRICE, URL (SEE http://www.redfin.com/buy-a-home/comparative-market-analysis FOR INFO ON PRICING), SOURCE, LISTING ID, ORIGINAL SOURCE, FAVORITE, INTERESTED, LATITUDE, LONGITUDE, IS SHORT SALE |
CategoriesArchives
May 2016

|
||
 RSS Feed
RSS Feed
