|
At the beginning of the week, I met with Julie to discuss and provide feedback on the interface she has been designing for our web app. We were able to agree on the color scheme, brainstormed ways to make the site more user friendly, and realized additional pages that will need to be added. My priority for this week was to get back to scraping data from our other sources. I wanted to get the smaller sets completed first, so I began researching sources that held all stadiums in the US. There were a couple of sources to choose from, but Wikipedia had the simplest structure for web scraping. They have a page that list every stadium, including: capacity, city, state, year opened, type, and tenant. Because the data needed was within one table, I was able to use Microsoft Excels PowerQuery plugin. It was really simple to use. All I needed to do was provide the url to the site that contained the table, and then the application would automatically parse the data and let you choose which section of the page you would like to scrape. Since I decided to keep everything in json format, I wrote a script to parse the csv file and convert it to json. 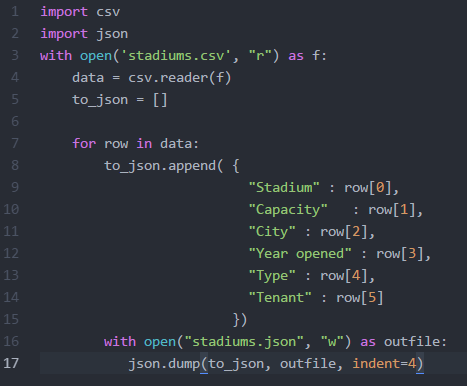 Since the source did not provide the address for the stadiums, I was interested in finding out whether or not Google's Geocoder will be able to handle requests when provided the name of the stadium. According to their documentation, it states that an address must be entered. I went ahead and tested it with one stadium name and I actually received a successful response with the accurate location data. Since that worked, I made a few adjustments to my script to include the requests library so I can make the API calls and obtain the responses. However, this did not provide location data for every stadium. There are some that list an empty list with the status of "ZERO_RESULTS". I will revisit the list to see how may stadiums are missing location data to see if it won't be too time consuming to enter the data manually.
I started researching the different real estate site that are out and many of them do not allow web scraping of their data, and their APIs are very restrictive, but they do allow 1000 calls per day. Trulia has an API, but they only return statistics in cities, counties, states, etc. I will continue to research other real-estate application and hope that I find more open data. If I do not, I can sign-up for a Trulia account and start making the 1000 calls per day.
0 Comments
This week, I continued work on trying to solve the issue reading the data I received from Great Schools in the desired format. After studying and testing the csv and python libraries I was finally able to figure out how to pull only the address in the format I needed.
As I had originally thought, the issue was due to how the data in the csv file was formatted. The way I was able to solve this issue was by reformatting it to a tuple structure. By reformatting it the following format, I was able to access the address without it splitting the city, state and zip: 'District_Name', 'School_Name', 'Address' What I was not aware of before was how the data was formatted after being read by the csv reader. When I opened the csv file in excel, or in my text editor, it was in the following format: ['<District>','<school>','<Address>'], but after it was read by the csv reader, it was wrapped by brackets and quotes ["['<District>','<school>','<Address>']"], which were causing the issue of printing in the incorrect format. I realized this by printing each row in the csv as it was being read; before, I was trying to only print the address and was not seeing the extra characters in the output. What I needed to do was remove the extra brackets and quotes from both ends. I was able to find some methods in pythons library that allowed me to complete this task: join, and string manipulation. Below is a snippet of the code used to reformat the csv data: with open('school_data.csv', "r") as f: data = csv.reader(f) for row in data: school_data = ','.join(row) school_data = str(school_data)[2:-2].split("', '") I tested this by using a sample data set of school information (for more time efficient testing). By getting it to the tuple format, I was able to print/access the full address, because python was able to differentiate the delimiter from the string elements. Since I was able to successfully obtain the address from the great schools data, I was able to look into writing the script to make use of Google's Geocoder API. This was a fairly simple task, because Google's geocoder html requests are straight forward. I needed to concurrently read in all of the addresses from the great schools data, make the html geocode request using python's requests library, then appending the found data to respective school's data in my Great Schools data-set. As I was writing the script, I was thinking about how our triple store will be implemented/created later in the project. I thought it would be nice to start working on tagging our data (make it machine readable) now, vs. having to tackle the issue later. Earlier in my research, I learned about JSON. There are tools like JSON-LD that would make our job of creating our triple store much easier. Since what I currently have is just the data, and not the corresponding identifier for each piece of data, I looked into how to convert it to JSON's key value pair format. After some time of researching how this can be done, I was able to accomplish this task by constructing a dictionary as I was parsing the csv file. Once I finalized writing the csv content to a dictionary format, I was able to use the json.dump() method to create the json encoded file. Finally, I was ready to replace the previous address information gathered from great schools to the geocoder location data. The benefit of having the geocoder location data for each of "places" is that it is constructed in a way that allows for more effective queries (street number, name, county, state, country, latitude, longitude are all individually tagged). Using their format we will be able to show data per state, county, city etc. which I feel would provide beneficial data for our users. In order to complete this task, I just needed to use python's requests library to make Google's geocoder html request by assigning a base address to a variable, then looping through my list of addresses produced earlier, store the json result into my created dictionary replacing the old location data from Great Schools: r = requests.get(base_addr+content[2]) geocoder_result = r.json() to_json.append( { "District" : content[0], "School" : content[1], "Location" : geocoder_result }) Google provides a geocoding API that takes in an address and outputs the corresponding latitude and longitude. However, there are usage limits to using server-side geocoding with a quota of 2,500 requests per IP per day. Google also has a limit for client-side geocoding, but is not a restrictive. It may block requests if all of the users are making requests at the same time. Since our application will have a limited dataset and is still in development, we can incrementally obtain the latitudes and longitudes for all of our address each day. When our application is actually deployed, we can use client-side scripts from Google's API to place markers on the map.
I decided to test the server side method on a portion of the school data I gathered from Great Schools. Since the geocoder required an address, I had to figure out how to pull only the address for each school from the csv file and use that as a parameter for the geocoder html request: Geocoder Request Format: https://maps.googleapis.com/maps/api/geocode/output?parameters I spent some time reading and going through the tutorials on their API site to ensure I fully understood how to use the tools that are available. I really wanted to become familiar with their Maps API, because I envision us using this for the application we develop so we can place markers for our found places and use their methods to determine which places are nearby to a selected real-estate property. While going through the tutorials, I found a way to use Google's API to return nearby places to a given address, and allows you to choose the type of places to be shown. This was a really cool find, because maybe we can use that to obtain general places for our map, for example: Libraries, restaurants, etc. I decided that this may be something I can revisit in the future if we have time, since we have already realized our datasets, and I am not sure how if it is possible to use their APIs to make that many requests. Once I was comfortable enough to begin testing their API against our Great Schools data, I started researching how to obtain only the address from the csv file containing all of our school data. I ran into some issues parsing the csv file to obtain a properly formatted address. The CSV file was in the following format: ['Abbotsford School District', 'Abbotsford Elementary School', '510 West Hemlock Street, Abbotsford, WI 54405'] ['Abbotsford School District', 'Abbotsford Middle/Senior High School', '510 West Hemlock Street, Abbotsford, WI 54405'] ... Whenever I would try to return the address I would only receive the address up to the first comma; the City, State and Zip was not returned. The reason this was happening was because I needed to use a comma as a delimiter, because each element was separated by a comma. Somehow, the reader was reading each line as a string, which is why the reader read each line as having five elements vs. three. I guess somewhere in the process of gathering and storing the data from Great Schools cause an issue with the csv generated document. I did not want to go back and re-write/test the great schools script I had written, because it takes almost 4 hours for the script to complete. Instead, I needed to find a way to write a script that would properly interpret what I have. I was unable to solve this issue yet, and will continue to research python libraries to help me resolve this issue. I will also look into seeing if it would be best to keep everything in json format, since that format will better align with storing our linked database (triple store) we will be creating. This week, we continued to work on scraping our selected data sources with the goal to scrap Spot Crime's data. The way Spot Crime's site was structured was different to Great Schools, so a different approach would need to be taken to get everything we need. What made this a bit more difficult was how they linked to the specific crime maps we needed. Writing the script to obtain all of the links to the state pages was simple, because the url structure for each state was consistent: spotcrime.com/<state abbreviation>. The difficulty lies on each of the state pages. The page consists of 3 tables of links:
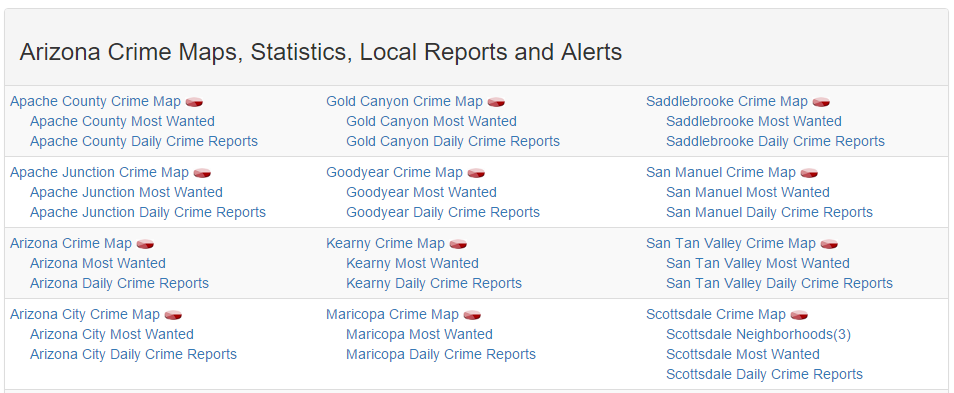 After studying the structure of the site, we figured that our best approach would be to pull the first a tag after every td tag. We should be able to do this, because each state page has the same class name for the tables, so knowing that will allow us to grab all of the tables from each state page. Once we do that, we can use python in conjunction with beautifulsoup libraries to locate the links for each crime map.
Each county's crime map page contains a list of crimes and provides the type, date, and location. When you select a crime instance, you are brought to a detailed description of the crime that lists the time, case number (sometimes), and a summary of the crime. Saul wanted to take on the task of pulling the crime maps and data. Since Saul took the lead on Spot Crime, I decided to focus on an issue I realized after reviewing the data we have received so far. In order for our application to be user friendly, it needs a map that displays schools, crime, and place within a given radius of their selected property. Many of the tools that can do this task require a latitude and longitude to be able to calculate the distance between two points. We do not have the latitude and longitude for the addresses we gathered so far, so I began looking for ways to get that information. I decided to take what I have learned so far with screen scraping and try to automate an online address to lat/long conversion tool. My idea would be to provide a list of address, and retrieve the corresponding lats/longs. I was not able to locate a conversion tool that did not use Javascript rendered pages. Because of this, I was not able to pull the data from the webpage like we did with others. Also, Beautiful Soup does not have the capability to submit forms, so I had to research other libraries that may be able to perform this task. After researching I found some information on Selenium. It is a tool used for functional/acceptance testing in web development. I was able to get the tool to work, but the issue was that I used a web-driver that actually ran the script live using a selected browser (opened a web-browser and performed the tasks I had written in the script). It was cool to watch the automated browser, but actually running the script for thousands of address would take way too long. For next week, I plan to figure out a way to gather the lat/long of all of our address, or see if there is another approach that we can take with only addresses. I would also like to move on to scraping our next data source. |
CategoriesArchives
May 2016

|
 RSS Feed
RSS Feed
