|
My Goals for this week was to get my Redfin scraper to work. I was finally able to find a way to automate the download with Selenium. I found that the reason I was unable to download was due to the additional prompt browsers display that give the option to either save, or open the file. Selenium has a method that allows you to set the webdriver to ignore the prompt and download in a given location. Once I applied the changes, I tested it by loading a site that had the download link: https://www.redfin.com/city/18607/AZ/Tempe. I then used selenium to search for and click the download link, and it worked. My next step was to make it automate the download for every city in the US. The reason I had to search by city was due to the input validation done on Redfin's website. The search box will not function unless provided an accepted format - City, State being the largest area that can be searched. Search by only It was actually quite difficult to get a list of every city in the US that was free. Zip codes are accepted, but there are a lot more zip codes then there are cities; therefore, the time it would take to complete the script would increase. When I did find a free resource, they were generally incomplete, or organized in a non-intuitive way. I eventually found what I needed, and was able to reformat it to be used as input for my script. I thought I had it figured out, but then I ran into a lot of issues when trying to automate the download for every city. First, there were a few checks I needed to include in the script to handle the faults on Redfin's site. One fault that would occur is when a city and state is provided that is not recognized by Redfin, it would display a pop-up window with suggestions for other cities. To handle this, I had to add a check to verify the current url did not change; if the url did not change, then I know the fault had occurred. If the fault occurred, I would reload the site, then search the next city. Another fault that I noticed was that it would sometimes load the page for a given city, but the city would not have any listings nor download link. To handle this fault, I included a try catch block to catch the NoSuchElementException that is thrown when the download link is not present. 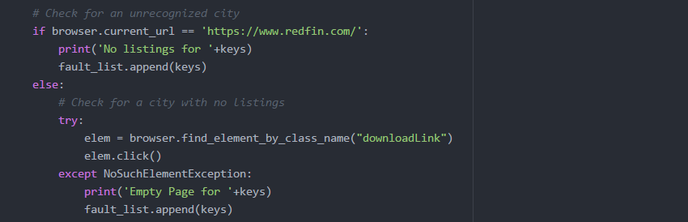 Once I handled the possible faults, I thought I was finished, but then I ran into other issues. The script would run fine for a few cities, then it would get buggy. There seemed to be random issues with Selenium loading a site, download the csv file, and finding elements. I monitored the script as it would run, then I would see it load a site for a city, download the csv file, then instead of following the script by going back to the main webpage redfin.com, it would instead skip to searching for the next city on the listings page. Below is a screenshot of an example:  As you can see, the site loaded for Tempe (see url), but after the download it did not go back to the main redfin.com, instead it searched Tolleson in the search box above. This would not be an issue if the site was able to recognize every city, but due to the fault explained earlier, if Tolleson was not in their list of valid cities, it would crash my script. I could not figure out why this would occur. My assumption would be that it was due to the inconsistent loading times, so I began researching the different wait methods. I first decided to bring in Python's time library to use the sleep function. This will force my script to stop for a given amount of time, then continue. It did seem to improve the script by completing a few more cities before crashing, but it would eventually crash. I knew that approach was risky, because the time for a page to load is inconsistent. I then found Selenium's explicit wait method that waits for a certain condition to occur before proceeding further in the code.
1 Comment
|
CategoriesArchives
May 2016

|
||
 RSS Feed
RSS Feed
