|
Now that I have figured out how to apply a context to our data using JSON-LD's syntax, we need to publish our data to be able to query against it in our web app. There are many options to publishing our data, and Dr. Bansal recommended Fuseki. To try it out, I installed Fuseki on my local machine. Fuseki is a SPARQL server. I am using it as a standalone server. We decided to go with Fuseki, because it's open source and supports JSON-LD. Once I installed the server, I was able to upload our JSON-LD documents. The Fuskei server provides a great interface that allows you to create your datasets, upload data, test SPARQL queries against your uploaded data. SPARQL is very similar to SQL, but there are some very distinct differences, that are confusing at first. The part that confused me at first was how you have to reference keys in your data. I was able to figure out the syntax and was able to produce valid queries against my data. Below is a basic SPARQL select statement to get all of the stadiums names: PREFIX schema: <http://schema.org/> As you can see, you can provide your query a prefix. This allows you to reference keys in your data without having to provide the entire URI; it just makes the queries more readable. The ?name is known as a SPARQL variable. SPARQL variables start with a ? and can match any node (resource or literal) in the dataset. Inside of the where clause is where you can see is where I can ask for all StadiumsOrArenas and names that are linked with the schema:name predicate. This is called a Triple Pattern. Triple Patterns are just like triples, except that any of the parts of a triple can be replaced with a variable. This is very powerful, because it allows us to discover unknown relationships.
I need to continue testing and running queries against our dataset to ensure I have properly defined our Schema that produces useful queries. This part of the project is very exciting, because this is actually what will set our application apart from any other real-estate application.
0 Comments
To begin attempting to apply a context to our data I chose to take a sample of our stadium data. The current state of a stadium JSON object is as follows:
{ "Capacity": "30000", "Tenant": "Troy Trojans", "Type": "Football", "Stadium": "Veterans Memorial Stadium", "Location": { ... (google geocoder results) }, "Year opened": "1950" } In order to apply a context to this instance, I can do the following: { "@context" : { "Stadium": "http://schema.org/name", "capacity": "http://schema.org/additionalProperty", "Type": "http://schema.org/brand", "Tenant": "http://schema.org/additionalProperty", "Location": "http://schema.org/address", "Year opened": "http://schema.org/foundingDate", }, "Capacity": "30000", "Tenant": "Troy Trojans", "Type": "Football", "Stadium": "Veterans Memorial Stadium", "Location": { ... (google geocoder results) }, "Year opened": "1950" } To test if the context I provided was valid, I can use JSON-LD's playground site. There are still more properties to be added to make it more useful, but I feel this approach is unrealistic due to how time consuming it will be. This method will need to be applied to every instance, causing a lot of overhead. Also, If I decide to add or change the context, I will need to do so for every instance. This issue is similar to css styling. styles can be embedded into html, added to the header of the document, or it can be linked from an external css file. The latter approach is generally a best practice, because maintenance becomes simpler and quicker. A JSON-LD also has a similar approach to deal with this issue. A .jsonld context file can be created, then an instance can link to the file to apply the context. This approach reduces overhead, and allows for simpler maintenance. I was able to refine the context and create a jsonld context file: { "@context": { "name": "http://schema.org/name", "geo": "http://schema.org/geo", "address": "https://schema.org/address", "latitude": { "@id": "http://schema.org/latitude", "@type": "xsd:float" }, "longitude": { "@id": "http://schema.org/longitude", "@type": "xsd:float" }, "brand": "https://schema.org/brand", "foundingDate": { "@id": "https://schema.org/foundingDate", "@type": "xsd:int" }, "teams": "https://schema.org/additionalProperty", "capacity": { "@id": "https://schema.org/additionalProperty", "@type": "xsd:int" }, "xsd": "http://www.w3.org/2001/XMLSchema#" } } The issue was is figuring out where to host the file, so I can link to it. I decided to store it in our github repo. The most recent stadium context file can be found here. Now that the context file is hosted, I can re-write our instances as followed: { "name": "Veterans Memorial Stadium", "teams": "Troy Trojans", "foundingDate": "1950", "@context": "https://raw.githubusercontent.com/slopez15/ASU-CREU2016/master/JSON-Data/stadiums_context.jsonld", "brand": "Football", "address": "Veterans Memorial Stadium, Veterans Dr, Coffeyville, KS 67337, USA", "@type": "https://schema.org/StadiumOrArena", "geo": { "latitude": 37.0706651, "@type": "GeoCoordinates", "longitude": -95.6415231 }, "capacity": "30000" } I was unable to complete any significant research this week. The time I did spend was researching JSON-LD's documentation on their site http://json-ld.org/. The examples they use in the documentation use a single instance of an object and is easy to understand,but my issue is we have to apply a context to multiple instances of pre-existing data. If I were to apply the concepts explained in the documentation, I will need to manually apply a context to every instance, which seems unrealistic. I will continue researching this issue through other resources.
The goal for this week was to convert our current JSON data to JSON-LD. I had watched some videos earlier in the semester that covered JSON-LD, and I had thought the process of converting JSON to JSON-LD would be quick and simple. I began researching JSON-LD's documentation to better understand how JSON-LD works. I found a really helpful resource that covers JSON-LD's syntax. After looking through this syntax, I realized this task would not be as simple as I thought. However, there is an aliasing feature that can allow me to map keywords in my current JSON documents to JSON-LD context keywords. I will need to test a subset of the data we have gathered to ensure I am able to successfully produce valid JSON-LD from pre-existing JSON data. I was not able to work on the conversions this week, because I spent a majority of my time building our Rails app. I had developed a Rails website for personal use, and I had already chose a cloud hosting service named Heroku for my personal site. Since I had the background knowledge of setting up a Rails app on Heroku, I chose to setup our Real Estate app the same way. I chose to Heroku's cloud hosting service, because it really makes managing and deploying apps easy (also, because they offer a free plan). I was able to build the skeleton for our web-app and deploy it via Heroku. Once the app was live, I began working on how we would manage our site. I connected the Github repo that houses our app to Heroku, and then setup automatic deployment. Anytime someone pushes to our master branch, the changes will automatically get deployed. Deploying this way is really useful for team oriented projects, because there is one central location for our source code. Heroku has it's own standalone client to manage your repo, but this can cause issues if Github and Heroku become out of sync. Also, I was able to setup Travis CI (Continuous Integration tool) to run tests before any changes to the code gets deployed. Since this is a Ruby on Rails app, it cannot be viewed locally in a browser like a standard html site. The only way to get a visual of any code changes was to deploy the changes. This is generally not good practice, because it's a live site. We need a way to test and view our local changes before deploying. To get around this issue, I was able to setup a development environment that allows you to run the rails server command that allows you to view the site the "localhost". I would like to add more Travis CI tests to run against any pushes to our master branch, but I am not familiar with the different tests for Ruby on Rails apps. This is not a priority, so I will look into this during my downtime. Now that we had the site up and running, and we now have a development environment, I decided to create a new branch to play with the design. I have been wanting to try out Google's material design framework, and this was a good opportunity to do so. I used the design prototype Julie put together as a source of inspiration for the layout. This framework allows you to easily create responsive websites that work across many device sizes through graceful degradation. The images below is what I currently have on the material-design branch. It is a basic responsive landing page. Once we finalize on a design, we can work on dynamically loading conent: Large Screen Display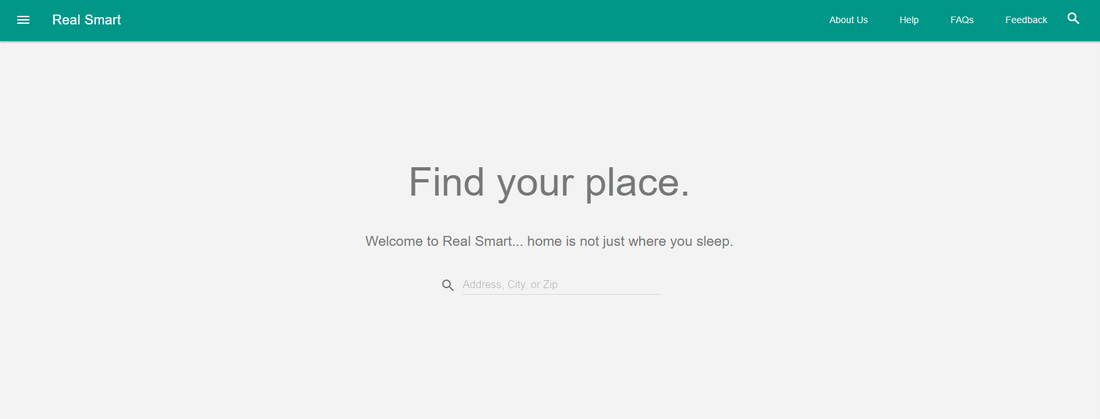 Graceful Degradation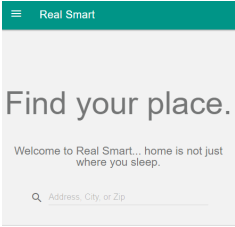 This week was very productive. I spent hours researching why my Redfin scraper appeared to be skipping statements causing it to crash. I finally learned that the reason this was happening was because when a selenium web driver interacts with a webpage is such a way that causes the page to load/reload, we have to also write a script that will stop the script from executing the next statement until the page has completed loading; Selenium does not know to wait for a page to load, so if the page does not load quick enough, the next statement will be executed to soon, and this is exactly what was happening to me. Thanks to Harry J.W. Percival, the author of Test-Driven Development with Python, he covers how to resolve this issue on his blog. I then took what I needed from that post and incorporated it into my script. To test the new wait method, I added a condition to only scrape Arizona properties. After a few hours, the script completed without any errors. I then felt confident enough to allow the script to scrape the remaining states. This process took 5 days to complete (slowness is the downside of using Selenium, because it requires an actual browser to make the calls).
Because the script goes to every city and downloads a unique csv file to a designated folder, I ended up with a folder with almost 9,000 csv files. The next step is to convert all of the data to JSON format, so I needed a way to combine all of the files into one. I did not want to do this manually, so I look into way to automate this process. After researching Pythons libraries and found a way to search for all csv files in a given directory and write each file into a new one. This worked out pretty well and I now have all of the property data I scraped from every state in one file. I have yet to convert the data to JSON. While the script was running, I took the time to organize all of my scrapers and data, then push them to our Github repository for this project. My Goals for this week was to get my Redfin scraper to work. I was finally able to find a way to automate the download with Selenium. I found that the reason I was unable to download was due to the additional prompt browsers display that give the option to either save, or open the file. Selenium has a method that allows you to set the webdriver to ignore the prompt and download in a given location. Once I applied the changes, I tested it by loading a site that had the download link: https://www.redfin.com/city/18607/AZ/Tempe. I then used selenium to search for and click the download link, and it worked. My next step was to make it automate the download for every city in the US. The reason I had to search by city was due to the input validation done on Redfin's website. The search box will not function unless provided an accepted format - City, State being the largest area that can be searched. Search by only It was actually quite difficult to get a list of every city in the US that was free. Zip codes are accepted, but there are a lot more zip codes then there are cities; therefore, the time it would take to complete the script would increase. When I did find a free resource, they were generally incomplete, or organized in a non-intuitive way. I eventually found what I needed, and was able to reformat it to be used as input for my script. I thought I had it figured out, but then I ran into a lot of issues when trying to automate the download for every city. First, there were a few checks I needed to include in the script to handle the faults on Redfin's site. One fault that would occur is when a city and state is provided that is not recognized by Redfin, it would display a pop-up window with suggestions for other cities. To handle this, I had to add a check to verify the current url did not change; if the url did not change, then I know the fault had occurred. If the fault occurred, I would reload the site, then search the next city. Another fault that I noticed was that it would sometimes load the page for a given city, but the city would not have any listings nor download link. To handle this fault, I included a try catch block to catch the NoSuchElementException that is thrown when the download link is not present. 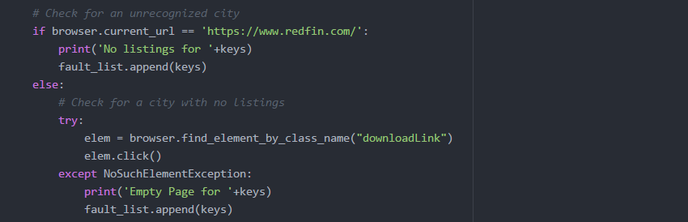 Once I handled the possible faults, I thought I was finished, but then I ran into other issues. The script would run fine for a few cities, then it would get buggy. There seemed to be random issues with Selenium loading a site, download the csv file, and finding elements. I monitored the script as it would run, then I would see it load a site for a city, download the csv file, then instead of following the script by going back to the main webpage redfin.com, it would instead skip to searching for the next city on the listings page. Below is a screenshot of an example:  As you can see, the site loaded for Tempe (see url), but after the download it did not go back to the main redfin.com, instead it searched Tolleson in the search box above. This would not be an issue if the site was able to recognize every city, but due to the fault explained earlier, if Tolleson was not in their list of valid cities, it would crash my script. I could not figure out why this would occur. My assumption would be that it was due to the inconsistent loading times, so I began researching the different wait methods. I first decided to bring in Python's time library to use the sleep function. This will force my script to stop for a given amount of time, then continue. It did seem to improve the script by completing a few more cities before crashing, but it would eventually crash. I knew that approach was risky, because the time for a page to load is inconsistent. I then found Selenium's explicit wait method that waits for a certain condition to occur before proceeding further in the code.
This weeks goal was to obtain real estate data. I began by researching the most common and well known real estate websites: Zillow, Trulia, and realtor.com. I was hoping one of these sites will have API's that are not too restricted. Zillow's API only allows you to obtain property data for a specified address, so we will not be able to obtain all of the properties that are on the market. Afterwards, I looked into Trulia's API and they only allowed you to review general data regarding cities and states, which will also not help us locating properties that are for sale. I then began looking into realtor.com, but I was not able to locate an API on their website. I learned that getting this data would not be simple, because of the importance these leads have in the world of real estate. I found blog posts on sites like Quora where other people were looking to obtain the same data, and I learned that MLS data is usually only provided to realtors and brokerages that are members of a specific MLS. After learning this, I had to resort to web scraping.
My next goal was to try to find a website with a friendly web-scraper format. Many of the sites only listed a few properties and were paginated, so writing a script for that may be complicated. Also, many of the sites were JavaScript rendered pages, which we are not able to scrape using the beautiful soup and standard Python libraries. I did find one website that provided a unique feature that I was not able to find on any other real estate website. redfin.com allows you to search for by city and returns a list of all properties for sale in the city. Not only does it provide a list, it provides a link to download the entire list in csv format! I was really excited to find this, because I thought it will make writing a scraper much simpler. After studying the sites url structure to see how I would go about getting every city's list, I found that a unique ID was given for each state, which will made writing the scraper a bit more complicated. Since the unique id was being used on the site, I will need to write a script to automate entries on their main search function. I need to pass every city in the US into the search field and then locate the download link on each site. This of course will require me to read JavaScript rendered pages. Since redfin.com contained JavaScript rendered pages, I knew that I would need to research methods that will allow me to scrape it. Saul also ran into this issue with the data he was gathering and was able to locate some tools that are said to scrape JavaScript rendered data. The two he introduced me to was Ghost.py and PhantomJS. After learning about the two, Ghost.py seemed familiar to Selenium, which was a tool I used when I was trying to use a JavaScript tool that provided the latitude and longitude for a given address. I was able to get that to work, but the performance was not good, because it actually opened a automated the steps provided in the script. The tool was mainly used for acceptance testing. What made Ghost.py different was that it performed the same tasks, but with a headless browser which improves performance. So I went through the installation process by installed Ghost.py, then I learned it required and additional library; I can either install pyside, or pyQT. The issue I had was since I was running Python 3.5, neither of those libraries was supported. I did not was to downgrade, because many of my other scripts relied on the 3.5 version. I then tried PhantomJS. PhantomJS is a standalone headless browser, so I can use selenium like I did before, but instead of calling a normal browser like Firefox to test the script, I will be able to use the PhantomJS headless browser. I wrote a quick script to run against the redfin site that will open the site, enter "Tempe, AZ" in the search box, then click on the download link. The script failed when it go to locating the search box by it's class name. I could not find a mistake in the code I wrote, so I tested it using Firefox instead of PhanomJS. Using Firefox it was able to find the search box, enter Tempe, and load the Tempe site with the list and download link, but failed when trying to locate the download link. After researching why PhantomJS would not work, a lot of people that had similar issues found that there was a bug and a way to get around it was by applying a window size to the PhantomJS browser. I tried this, but continued to have the same issue. I was not able to find a solution to the PhantomJS issue, so I decided to stick to selenium and Firefox, but I still needed to figure out the issue not being able to click the download link. After spending some time researching and testing, I found that I made a mistake writing the click statement, so I made the adjustment and confirmed that my code is in fact locating the download link. The issue I had next was getting the click method to actually download the file. I read online that I could try adjusting my browser's download setting to not prompt and automatically store downloads in a specific folder. After trying, it still did not download. I will need to continue to research this issue. Once I am able to get the download link to work, I will be able to gather all properties for sale in the US along with the following data: SALE TYPE, HOME TYPE, ADDRESS, CITY, STATE, ZIP, LIST PRICE, BEDS, BATHS, LOCATION, SQFT, LOT SIZE, YEAR BUILT, PARKING SPOTS, PARKING TYPE, DAYS ON MARKET, STATUS, NEXT OPEN HOUSE DATE, NEXT OPEN HOUSE START TIME, NEXT OPEN HOUSE END TIME, RECENT REDUCTION DATE, ORIGINAL LIST PRICE, LAST SALE DATE, LAST SALE PRICE, URL (SEE http://www.redfin.com/buy-a-home/comparative-market-analysis FOR INFO ON PRICING), SOURCE, LISTING ID, ORIGINAL SOURCE, FAVORITE, INTERESTED, LATITUDE, LONGITUDE, IS SHORT SALE At the beginning of the week, I met with Julie to discuss and provide feedback on the interface she has been designing for our web app. We were able to agree on the color scheme, brainstormed ways to make the site more user friendly, and realized additional pages that will need to be added. My priority for this week was to get back to scraping data from our other sources. I wanted to get the smaller sets completed first, so I began researching sources that held all stadiums in the US. There were a couple of sources to choose from, but Wikipedia had the simplest structure for web scraping. They have a page that list every stadium, including: capacity, city, state, year opened, type, and tenant. Because the data needed was within one table, I was able to use Microsoft Excels PowerQuery plugin. It was really simple to use. All I needed to do was provide the url to the site that contained the table, and then the application would automatically parse the data and let you choose which section of the page you would like to scrape. Since I decided to keep everything in json format, I wrote a script to parse the csv file and convert it to json. 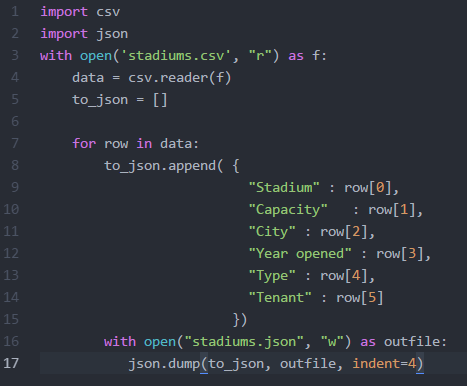 Since the source did not provide the address for the stadiums, I was interested in finding out whether or not Google's Geocoder will be able to handle requests when provided the name of the stadium. According to their documentation, it states that an address must be entered. I went ahead and tested it with one stadium name and I actually received a successful response with the accurate location data. Since that worked, I made a few adjustments to my script to include the requests library so I can make the API calls and obtain the responses. However, this did not provide location data for every stadium. There are some that list an empty list with the status of "ZERO_RESULTS". I will revisit the list to see how may stadiums are missing location data to see if it won't be too time consuming to enter the data manually.
I started researching the different real estate site that are out and many of them do not allow web scraping of their data, and their APIs are very restrictive, but they do allow 1000 calls per day. Trulia has an API, but they only return statistics in cities, counties, states, etc. I will continue to research other real-estate application and hope that I find more open data. If I do not, I can sign-up for a Trulia account and start making the 1000 calls per day. This week, I continued work on trying to solve the issue reading the data I received from Great Schools in the desired format. After studying and testing the csv and python libraries I was finally able to figure out how to pull only the address in the format I needed.
As I had originally thought, the issue was due to how the data in the csv file was formatted. The way I was able to solve this issue was by reformatting it to a tuple structure. By reformatting it the following format, I was able to access the address without it splitting the city, state and zip: 'District_Name', 'School_Name', 'Address' What I was not aware of before was how the data was formatted after being read by the csv reader. When I opened the csv file in excel, or in my text editor, it was in the following format: ['<District>','<school>','<Address>'], but after it was read by the csv reader, it was wrapped by brackets and quotes ["['<District>','<school>','<Address>']"], which were causing the issue of printing in the incorrect format. I realized this by printing each row in the csv as it was being read; before, I was trying to only print the address and was not seeing the extra characters in the output. What I needed to do was remove the extra brackets and quotes from both ends. I was able to find some methods in pythons library that allowed me to complete this task: join, and string manipulation. Below is a snippet of the code used to reformat the csv data: with open('school_data.csv', "r") as f: data = csv.reader(f) for row in data: school_data = ','.join(row) school_data = str(school_data)[2:-2].split("', '") I tested this by using a sample data set of school information (for more time efficient testing). By getting it to the tuple format, I was able to print/access the full address, because python was able to differentiate the delimiter from the string elements. Since I was able to successfully obtain the address from the great schools data, I was able to look into writing the script to make use of Google's Geocoder API. This was a fairly simple task, because Google's geocoder html requests are straight forward. I needed to concurrently read in all of the addresses from the great schools data, make the html geocode request using python's requests library, then appending the found data to respective school's data in my Great Schools data-set. As I was writing the script, I was thinking about how our triple store will be implemented/created later in the project. I thought it would be nice to start working on tagging our data (make it machine readable) now, vs. having to tackle the issue later. Earlier in my research, I learned about JSON. There are tools like JSON-LD that would make our job of creating our triple store much easier. Since what I currently have is just the data, and not the corresponding identifier for each piece of data, I looked into how to convert it to JSON's key value pair format. After some time of researching how this can be done, I was able to accomplish this task by constructing a dictionary as I was parsing the csv file. Once I finalized writing the csv content to a dictionary format, I was able to use the json.dump() method to create the json encoded file. Finally, I was ready to replace the previous address information gathered from great schools to the geocoder location data. The benefit of having the geocoder location data for each of "places" is that it is constructed in a way that allows for more effective queries (street number, name, county, state, country, latitude, longitude are all individually tagged). Using their format we will be able to show data per state, county, city etc. which I feel would provide beneficial data for our users. In order to complete this task, I just needed to use python's requests library to make Google's geocoder html request by assigning a base address to a variable, then looping through my list of addresses produced earlier, store the json result into my created dictionary replacing the old location data from Great Schools: r = requests.get(base_addr+content[2]) geocoder_result = r.json() to_json.append( { "District" : content[0], "School" : content[1], "Location" : geocoder_result }) Google provides a geocoding API that takes in an address and outputs the corresponding latitude and longitude. However, there are usage limits to using server-side geocoding with a quota of 2,500 requests per IP per day. Google also has a limit for client-side geocoding, but is not a restrictive. It may block requests if all of the users are making requests at the same time. Since our application will have a limited dataset and is still in development, we can incrementally obtain the latitudes and longitudes for all of our address each day. When our application is actually deployed, we can use client-side scripts from Google's API to place markers on the map.
I decided to test the server side method on a portion of the school data I gathered from Great Schools. Since the geocoder required an address, I had to figure out how to pull only the address for each school from the csv file and use that as a parameter for the geocoder html request: Geocoder Request Format: https://maps.googleapis.com/maps/api/geocode/output?parameters I spent some time reading and going through the tutorials on their API site to ensure I fully understood how to use the tools that are available. I really wanted to become familiar with their Maps API, because I envision us using this for the application we develop so we can place markers for our found places and use their methods to determine which places are nearby to a selected real-estate property. While going through the tutorials, I found a way to use Google's API to return nearby places to a given address, and allows you to choose the type of places to be shown. This was a really cool find, because maybe we can use that to obtain general places for our map, for example: Libraries, restaurants, etc. I decided that this may be something I can revisit in the future if we have time, since we have already realized our datasets, and I am not sure how if it is possible to use their APIs to make that many requests. Once I was comfortable enough to begin testing their API against our Great Schools data, I started researching how to obtain only the address from the csv file containing all of our school data. I ran into some issues parsing the csv file to obtain a properly formatted address. The CSV file was in the following format: ['Abbotsford School District', 'Abbotsford Elementary School', '510 West Hemlock Street, Abbotsford, WI 54405'] ['Abbotsford School District', 'Abbotsford Middle/Senior High School', '510 West Hemlock Street, Abbotsford, WI 54405'] ... Whenever I would try to return the address I would only receive the address up to the first comma; the City, State and Zip was not returned. The reason this was happening was because I needed to use a comma as a delimiter, because each element was separated by a comma. Somehow, the reader was reading each line as a string, which is why the reader read each line as having five elements vs. three. I guess somewhere in the process of gathering and storing the data from Great Schools cause an issue with the csv generated document. I did not want to go back and re-write/test the great schools script I had written, because it takes almost 4 hours for the script to complete. Instead, I needed to find a way to write a script that would properly interpret what I have. I was unable to solve this issue yet, and will continue to research python libraries to help me resolve this issue. I will also look into seeing if it would be best to keep everything in json format, since that format will better align with storing our linked database (triple store) we will be creating. |
CategoriesArchives
May 2016

|
||
 RSS Feed
RSS Feed
